
R을 이용한 JOISS 관측자료 활용
- R다운로드 및 설치
- JOISS 관측자료 다운로드 및 준비
- R에서 JOISS 데이터 불러오기
- R에서 JOISS 데이터 전처리하기
- 데이터 기초 통계 시각화
- 데이터 공간분포 시각화
- 데이터 시계열 시각화
- 상향식 접근법을 통한 데이터분석
· R다운로드 및 설치 TOP
JOISS데이터를 활용하기 위해 R을 다운로드하여 설치해 보도록 하겠습니다.
R은 오픈소스이므로 무료로 다운로드 가능합니다.
R 공식 홈페이지 : https://www.r-project.org/
다운로드 페이지 : https://cloud.r-project.org/
먼저 R 다운로드 페이지에 접속하여 사용하는 os를 선택합니다.
(본 튜토리얼은 윈도우 사용을 기준으로 작성하였습니다.)
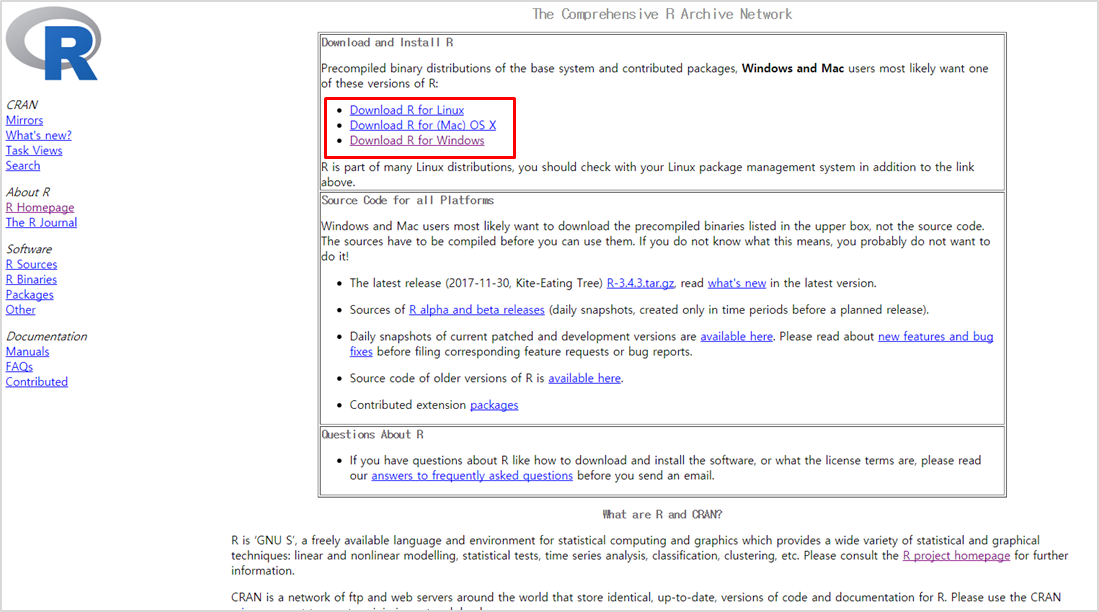
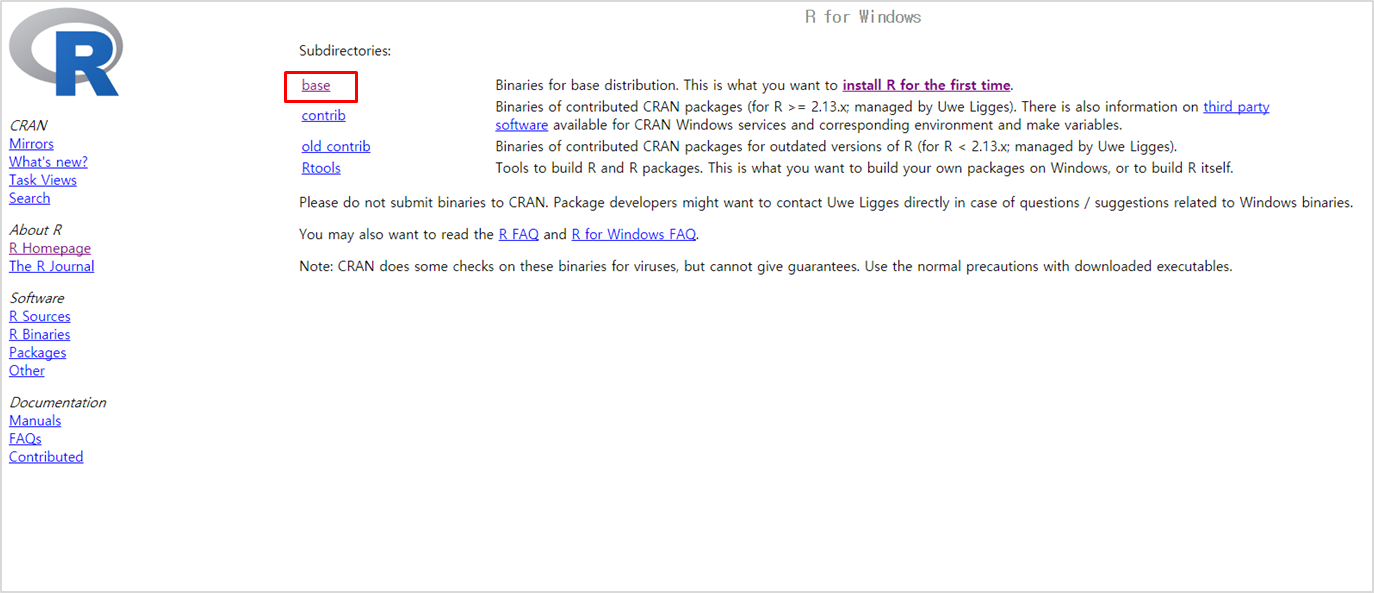
base를 클릭하신 후 최신버전의 R을 다운로드 합니다.
다운로드 받은 설치파일을 실행하여 R을 설치합니다.
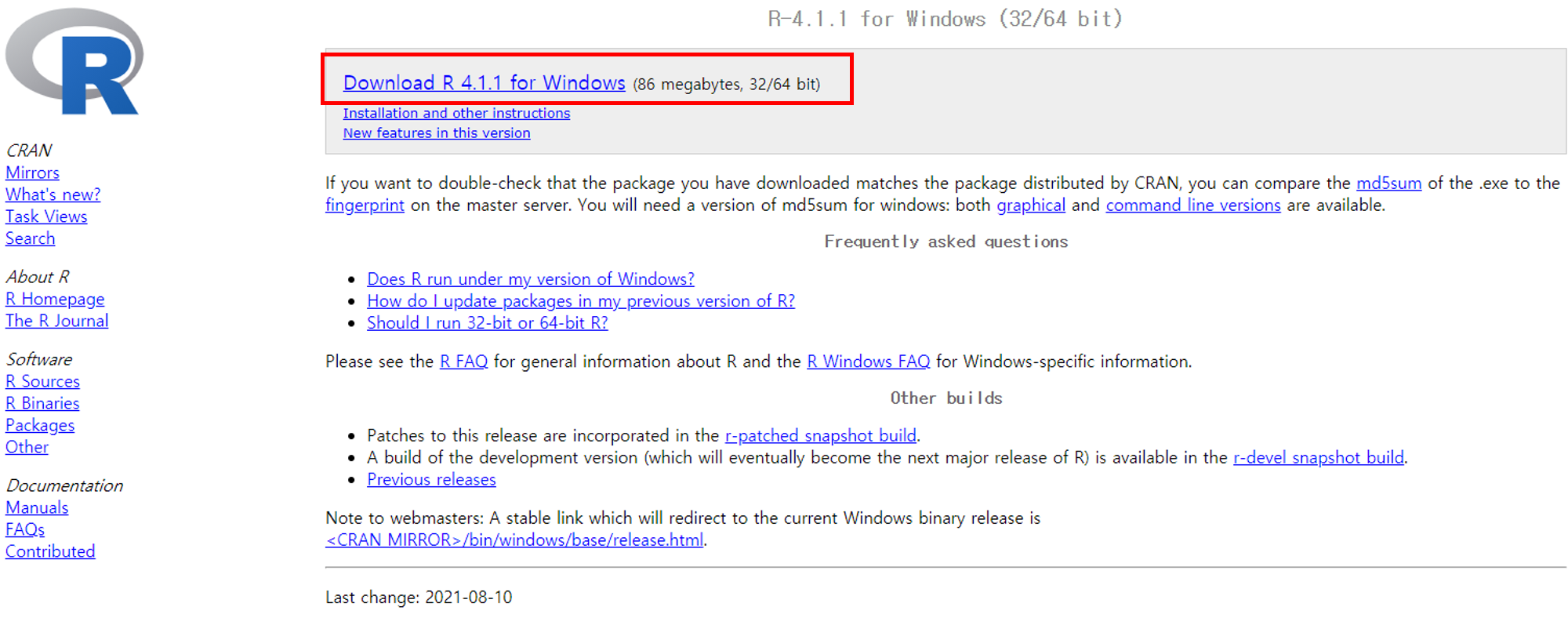
다운로드 받은 R설치파일을 실행하여 R을 설치합니다.
R설치가 완료되었다면 이번에는 R을 보다 편리하게 사용할 수 있도록 도와주는 R Studio를 다운로드 합니다.
아래의 링크에 접속후 스크롤을 내려서 사용하는 OS에 맞는 R Studio를 다운로드 합니다.
R Studio 다운로드 페이지 : https://www.rstudio.com/products/rstudio/download/
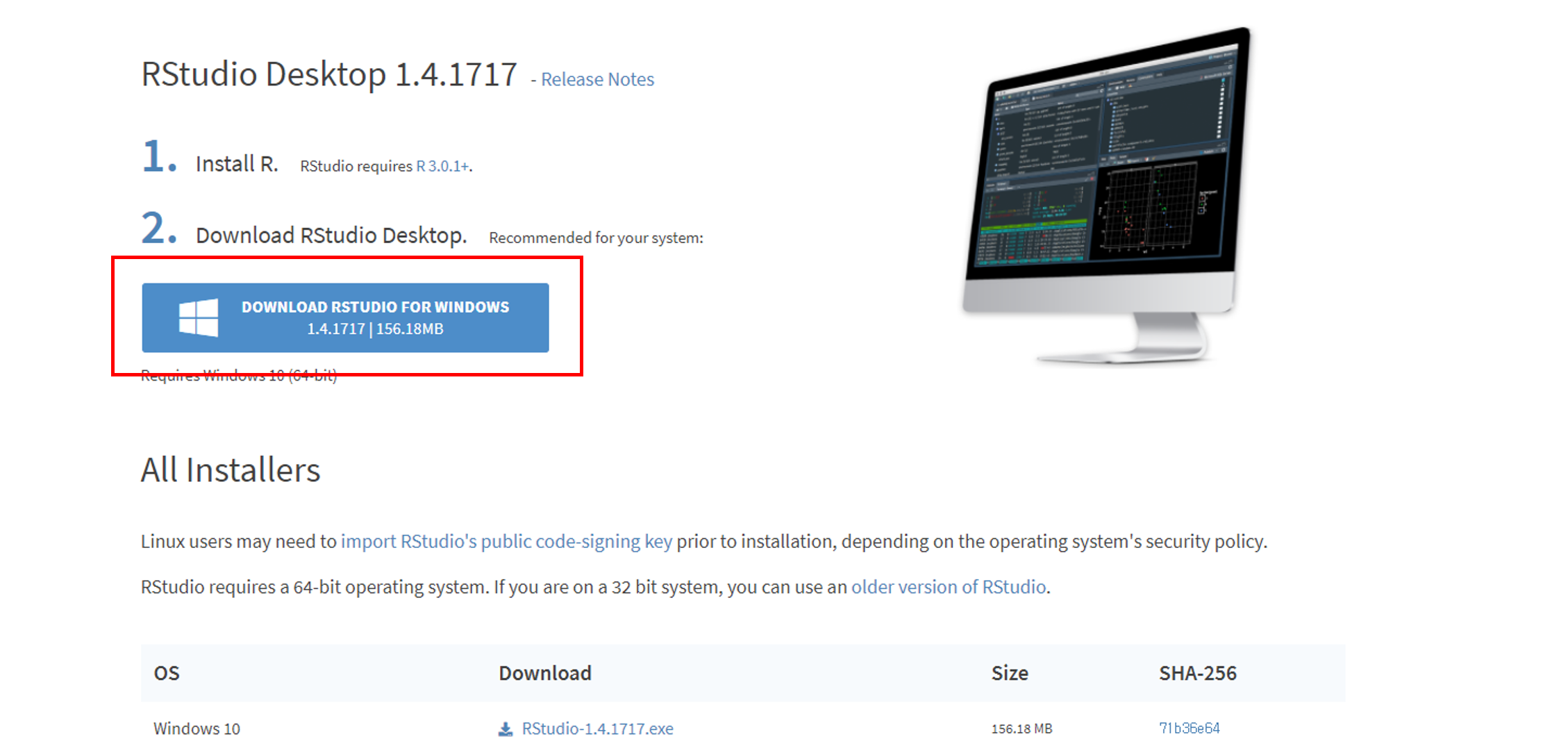
다운로드가 완료되었다면 R Studio를 실행합니다.
R Studio를 실행하면 설치한 R의 버전(예, 3.4.3) 아래와 같은 확인 및 인터페이스 화면을 확인할 수 있습니다.
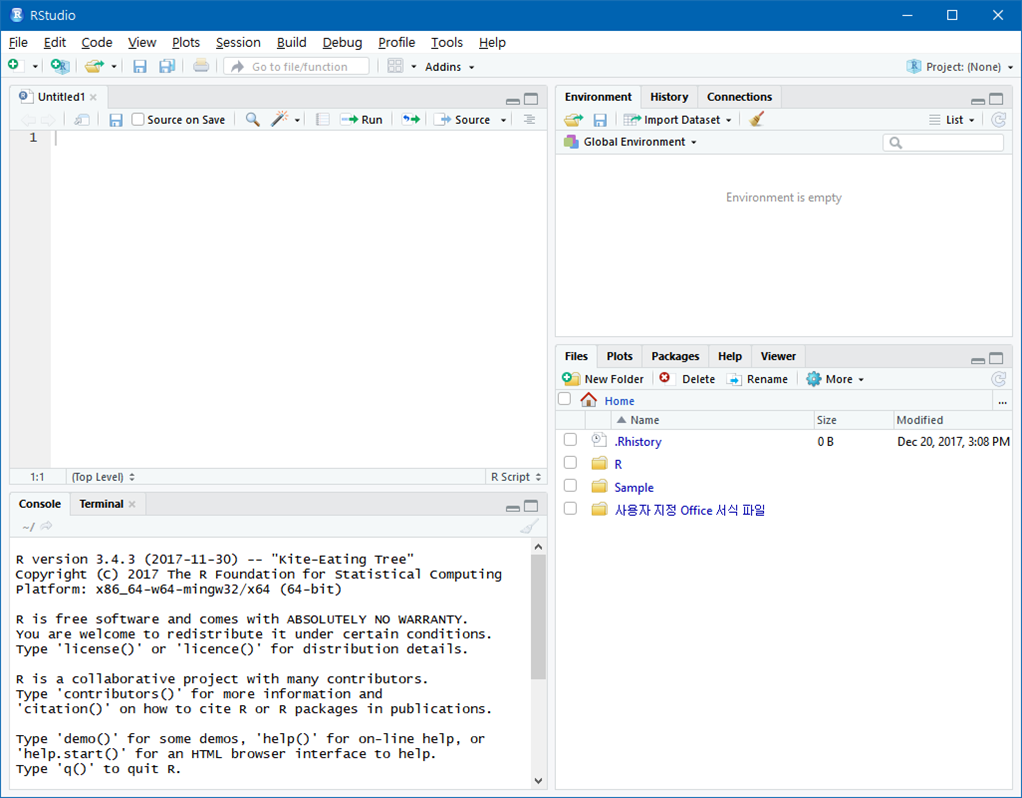
여기서, R Studio의 한글 설정을 위해
Tools -> Global Option을 클릭합니다.
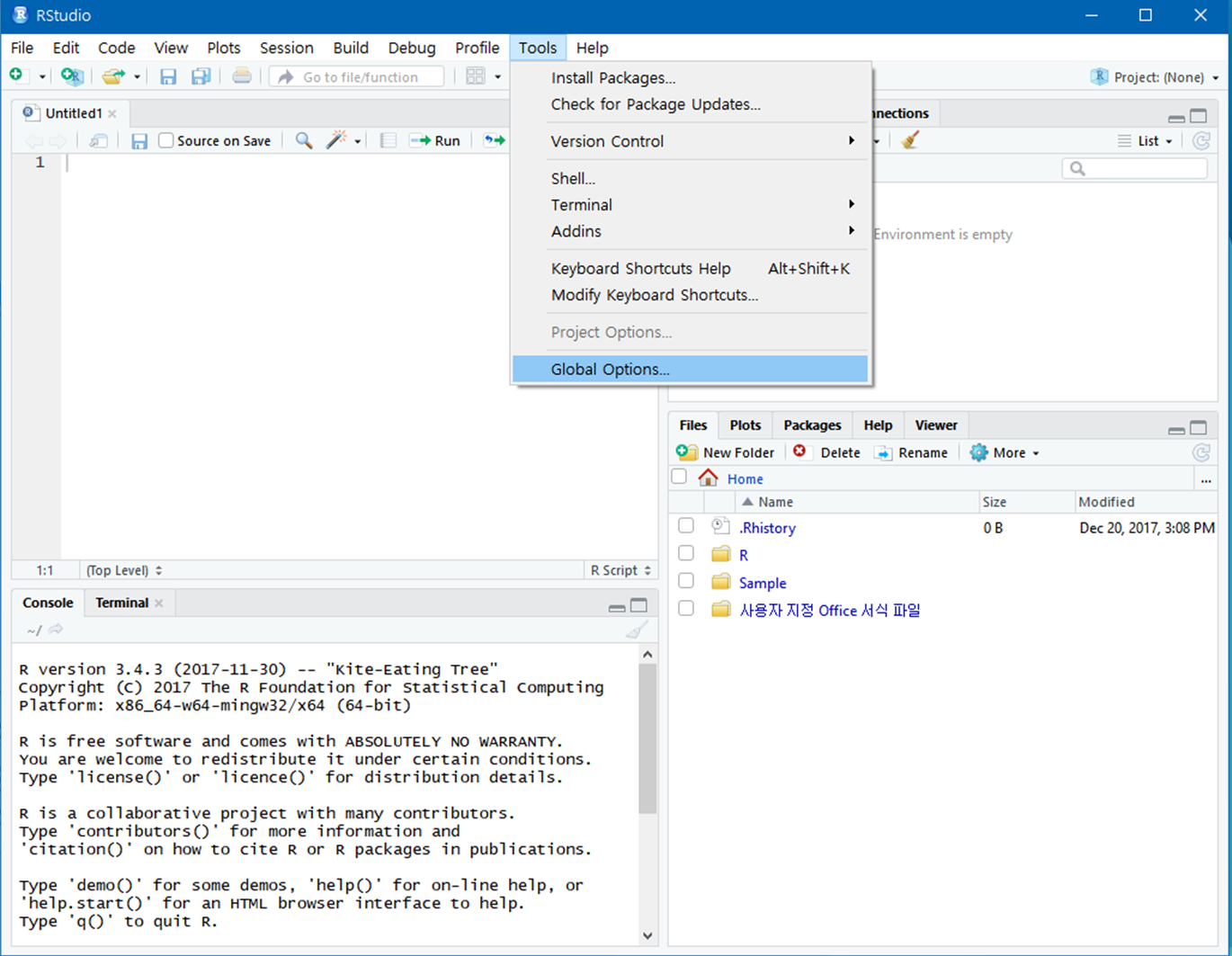
다음으로는 아래와같이
Code -> Saving으로 이동한 후 Default text encoding의
change 버튼을 클릭합니다.
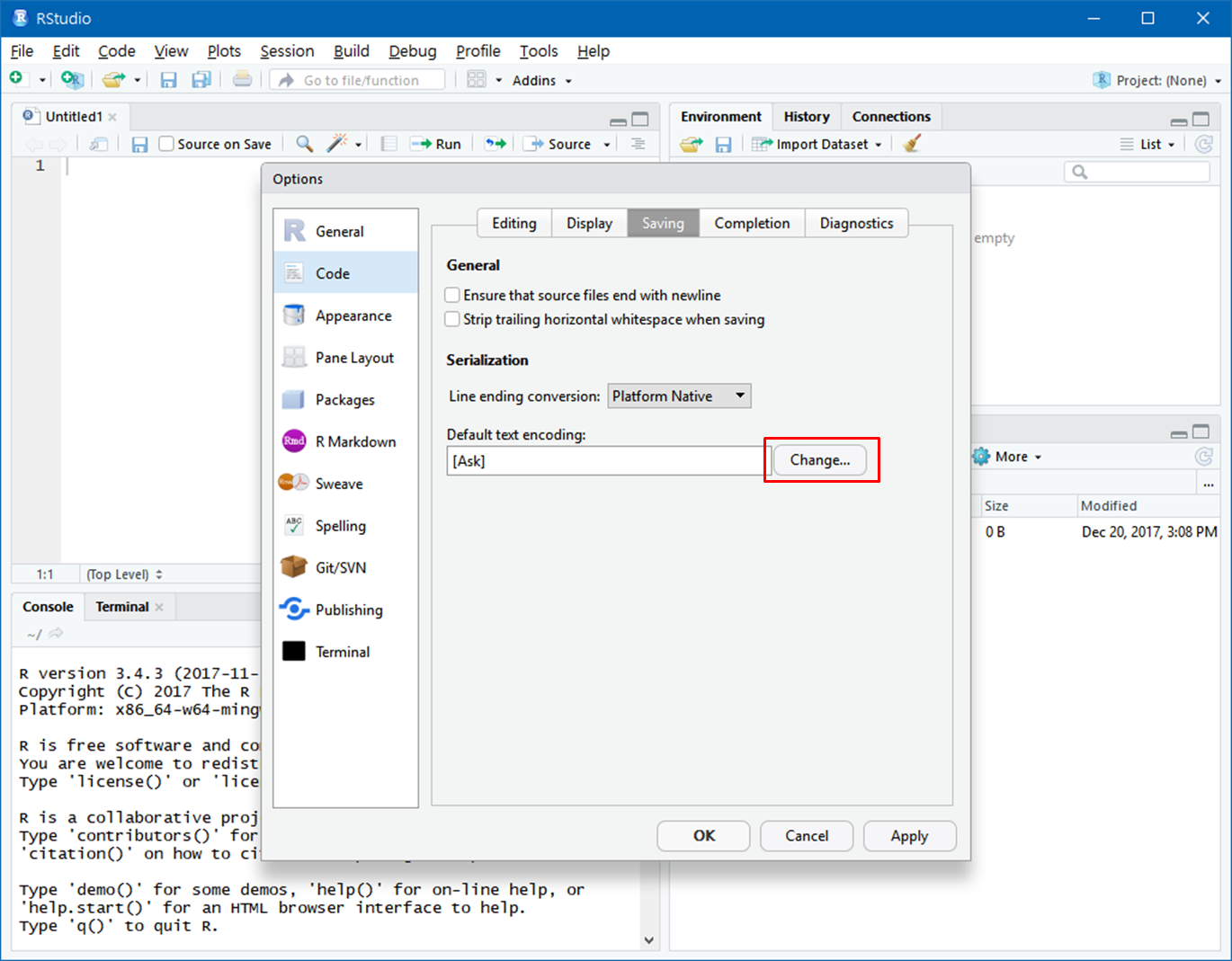
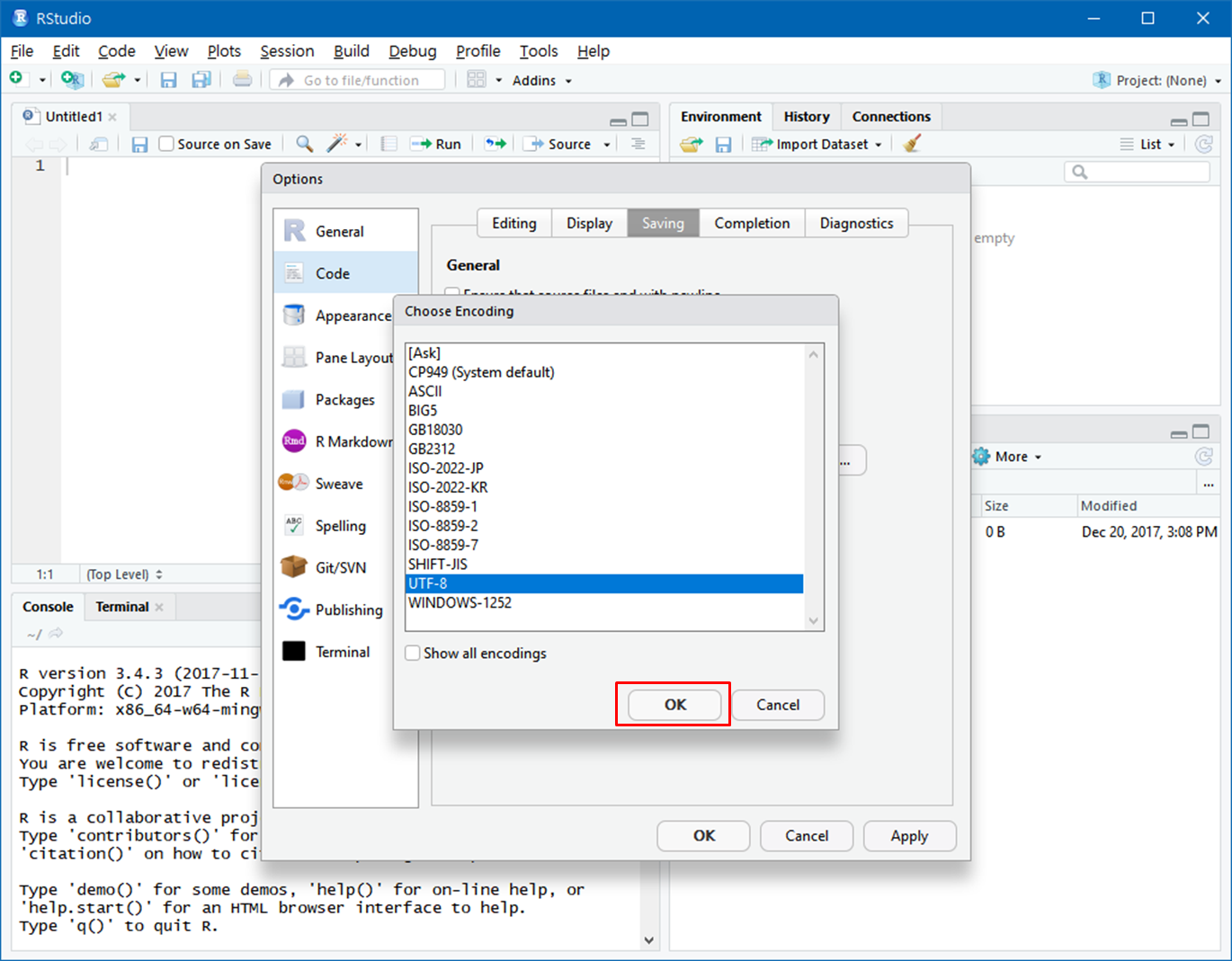
이것으로 R과 R Studio 설치 및 기본 설정을 마쳤습니다.
이외에도 R Studio의 Global Option설정을 통해 작업환경의 색상 및 크기를 설정할 수 있으니 시작하기전 사용자에 맞는 환경을 설정하는 것이 좋습니다.
준비가 완료되었다면 다음 튜토리얼을 통해 JOISS 데이터를 다운로드 받고 R에서 활요하는 방법을 배워보도록 하겠습니다.
· JOISS 관측자료 다운로드 및 준비 TOP
R에서 JOISS 관측자료를 시각화하고 활용하기 위해 샘플 데이터로 다음과 같은 데이터를 준비해 봅시다.
검색어 입력 : 정선해양관측_2015
검색 결과 중 ‘정선해양관측_2015_profile_chemical_unknown’ 데이터셋의 체크박스를 클릭 후 ‘ADD TO BASKET’ 버튼을 클릭하면 장바구니 리스트에 추가됩니다. 추가된 데이터는 장바구니 페이지에서 다운로드할 수 있습니다.
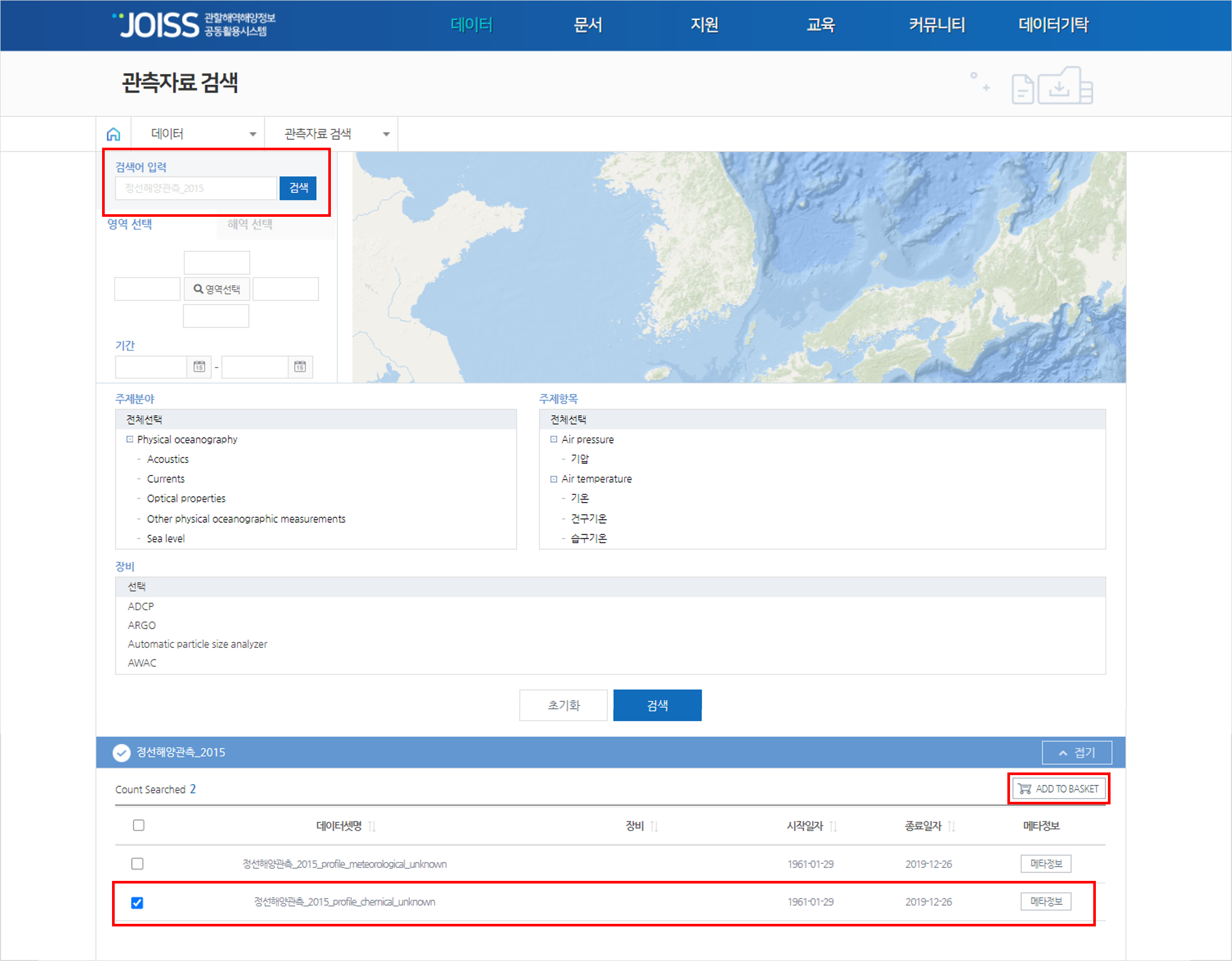
다운로드 받은 데이터는 아래의 그림과 같이 1개의 csv파일로 생성되며 파일을 열어보면 크게 4개의 분류(1.사업메타 2.인용문구, 3.데이터)로 이루어져 있습니다.
· R에서 JOISS 데이터 불러오기 TOP
JOISS에서 다운로드 받은 파일을 아래 코드를 통해 R에서 바로 불러올 수 있습니다.
파일내 주석 처리된 메타정보의 경우 자동으로 필터링 되므로 다운받으신 자료 그대로 사용하시기 바랍니다.
● 불러올 JOISS데이터가 저장된 폴더의 경로설정 및 파일명 지정후 데이터를 불러옵니다.
##
setwd
(
"C:/Users/myk09/Desktop/R/"
)
# 파일경로 지정 (경로에서 '\'는 '/'로 변경 필수!)
dataset_file_name <-
"정선해양관측_2015_profile_chemical_unknown.csv"
# 파일명 지정
# read csv file with out comment lines
removed_row <-
length
(
grep
(
"/.*"
,
readLines
(dataset_file_name)))
joiss_data <-
read.csv
(dataset_file_name, skip = removed_row, header = F, stringsAsFactors=
FALSE)
joiss_data_colnames <-
read.csv
(dataset_file_name, skip = (removed_row-1), header = F, nrows = 1, as.is = T)
colnames
(joiss_data) <- joiss_data_colnames[1, 1:
ncol
(joiss_data)]
# qc컬럼 삭제하기
joiss_data <- joiss_data[,
grepl
(
"_qc"
,
colnames
(joiss_data)) == F]
rm(removed_row)
rm(dataset_file_name)
rm(joiss_data_colnames)
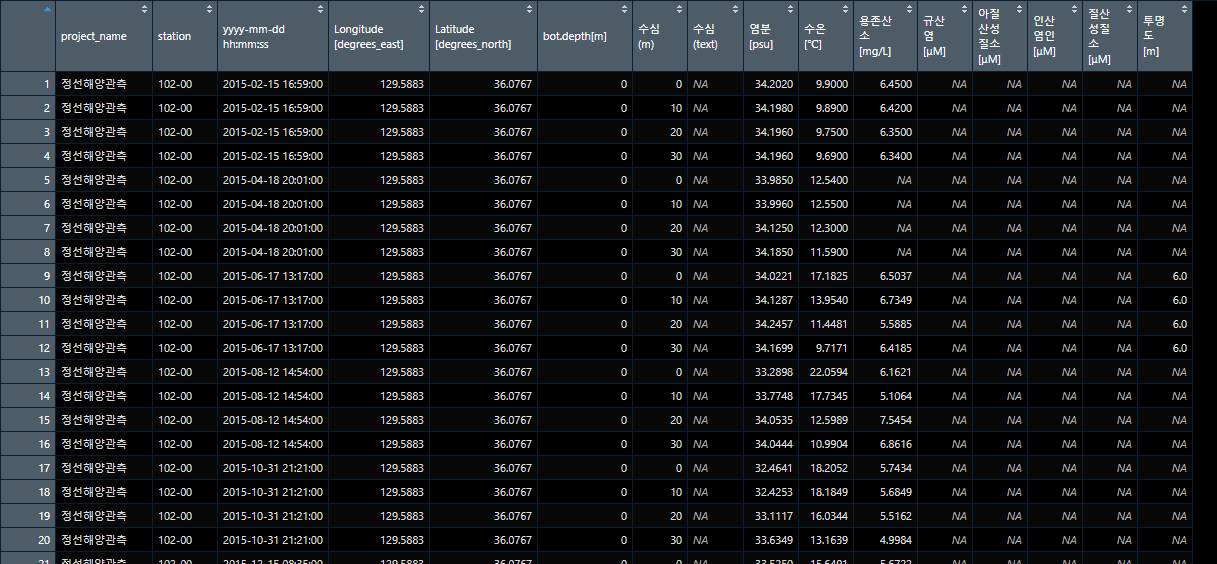
# 불러온 JOISS데이터 확인하기
View(joiss_data)
|
· R에서 JOISS 데이터 전처리하기 TOP
분석에 용이한 데이터구조로 변형하기 위해 R package reshape2를 활용하여 데이터 전처리를 진행하겠습니다.
먼저 R에서 패키지를 설치하기 위해서는 install.packages() 함수를 사용합니다.
아래의 소스코드를 실행하여 패키지를 설치합니다.
install.packages("reshape2") |
패키지가 설치되었다면 아래의 소스코드를 실행하여 joiss_data 데이터셋을 melt하여
data1변수에 정리해 보겠습니다.
##
library(reshape2)
## 데이터 컬럼명(항목) 확인
colnames(joiss_data)
## 필요한 데이터만 추출하여 파라메터에 저장(염분)
data1 <- melt(data = joiss_data,
id = c("Station", "yyyy-mm-dd hh:mm:ss", "Longitude [degrees_east]", "Latitude [degrees_north]", "수심(m)"),
measure.vars = c("염분[psu]") # 필요한 항목입력하여 필터
, na.rm = T)
data1$`yyyy-mm-dd hh:mm:ss` <- as.POSIXct(data1$`yyyy-mm-dd hh:mm:ss`)
str(data1) # 데이터 구조 확인
summary(data1)# 데이터 요약 확인
|
data1 변수에
염분자료가 제대로 입력되었는지 확인한 후 다음 분석을 진행 합니다.
· 데이터 기초 통계 시각화 TOP
전처리되어 data1변수에
입력된 joiss 데이터를 R 시각화 패키지인 ggplot2를 활용하여
히스토그램, 박스플롯, 월평균분포 등 원하는 정보를 쉽게 시각화 할 수 있습니다.
아래의 소스코드를 입력하여 p1~p4에 각각 시각화 이미지를 입력합니다.
## require(ggplot2)## histogram# p1 <- ggplot(data1, aes(x = value)) + theme_bw( ) + # geom_histogram(color="#034c7a", fill="#ffffff") + geom_density(color = "#ff0000")p1 <- ggplot(data1, aes(value)) + theme_bw( ) + geom_histogram(aes(y = ..density..), alpha = 0.7, color="#034c7a", fill="#b9cfe7") + geom_density(fill = "#ff4d4d", alpha = 0.2) + xlab(unique(data1$variable)) + ggtitle("Histogram with density curve")# Generate normal q-q ploty <- quantile(sort(data1$value), c(0.25, 0.75)) # Find the 1st and 3rd quartilesx <- qnorm( c(0.25, 0.75)) # Find the matching normal values on the x-axisslope <- diff(y) / diff(x) # Compute the line slopeint <- y[1] - slope * x[1] # Compute the line interceptp2 <- ggplot(data1, aes(sample = value)) + theme_bw( ) + stat_qq(distribution = qnorm, color="#034c7a", fill="#b9cfe7", shape = 1) + geom_abline(intercept = int, slope = slope, color = "#ff0000") + ylab(unique(data1$variable)) + ggtitle("normal Q-Q plot")# box-plotp3 <- ggplot(data1, aes(variable, value)) + theme_bw( ) + geom_boxplot(color="#034c7a", fill="#b9cfe7",alpha = 0.3 , outlier.colour = "#ff0000", outlier.shape = 1) + ggtitle("Box-plot")# bar_chart(monthly) p4 <- ggplot(data1, aes(format(as.POSIXct(data1$`yyyy-mm-dd hh:mm:ss`), "%m"), value)) + theme_bw( ) + geom_bar(stat = "summary", fun.y = "mean", color="#034c7a", fill="#b9cfe7", width = 0.5) + xlab("month") + ylab(paste0(unique(data1$variable),"_avg")) + ylim(0,max(data1$value)*1.2) + ggtitle("Bar chart(average by month) ") |
각 변수에 입력된 plot들을 하나씩 확인 할 수도 있으며, 한페이지에 확인할 수도 있습니다.
##plot 확인## histogramp1# q-q plotp2# box-plotp3# bar_chart(monthly)p4 |
여러 plot을 한번에 확인하기 위해 아래의 함수를 적용시킨 후 실행시킵니다.
############################################################################ Multiple plot function###########################################################################multiplot <- function(..., plotlist=NULL, file, cols=1, layout=NULL) { require(grid) # Make a list from the ... arguments and plotlist plots <- c(list(...), plotlist) numPlots = length(plots) # If layout is NULL, then use 'cols' to determine layout if (is.null(layout)) { # Make the panel # ncol: Number of columns of plots # nrow: Number of rows needed, calculated from # of cols layout <- matrix(seq(1, cols * ceiling(numPlots/cols)), ncol = cols, nrow = ceiling(numPlots/cols)) } if (numPlots==1) { print(plots[[1]]) } else { # Set up the page grid.newpage() pushViewport(viewport(layout = grid.layout(nrow(layout), ncol(layout)))) # Make each plot, in the correct location for (i in 1:numPlots) { # Get the i,j matrix positions of the regions that contain this subplot matchidx <- as.data.frame(which(layout == i, arr.ind = TRUE)) print(plots[[i]], vp = viewport(layout.pos.row = matchidx$row, layout.pos.col = matchidx$col)) } }}####################################################################################################################################################### muliple plot 실행multiplot(p1, p2, p3, p4, cols=2) |
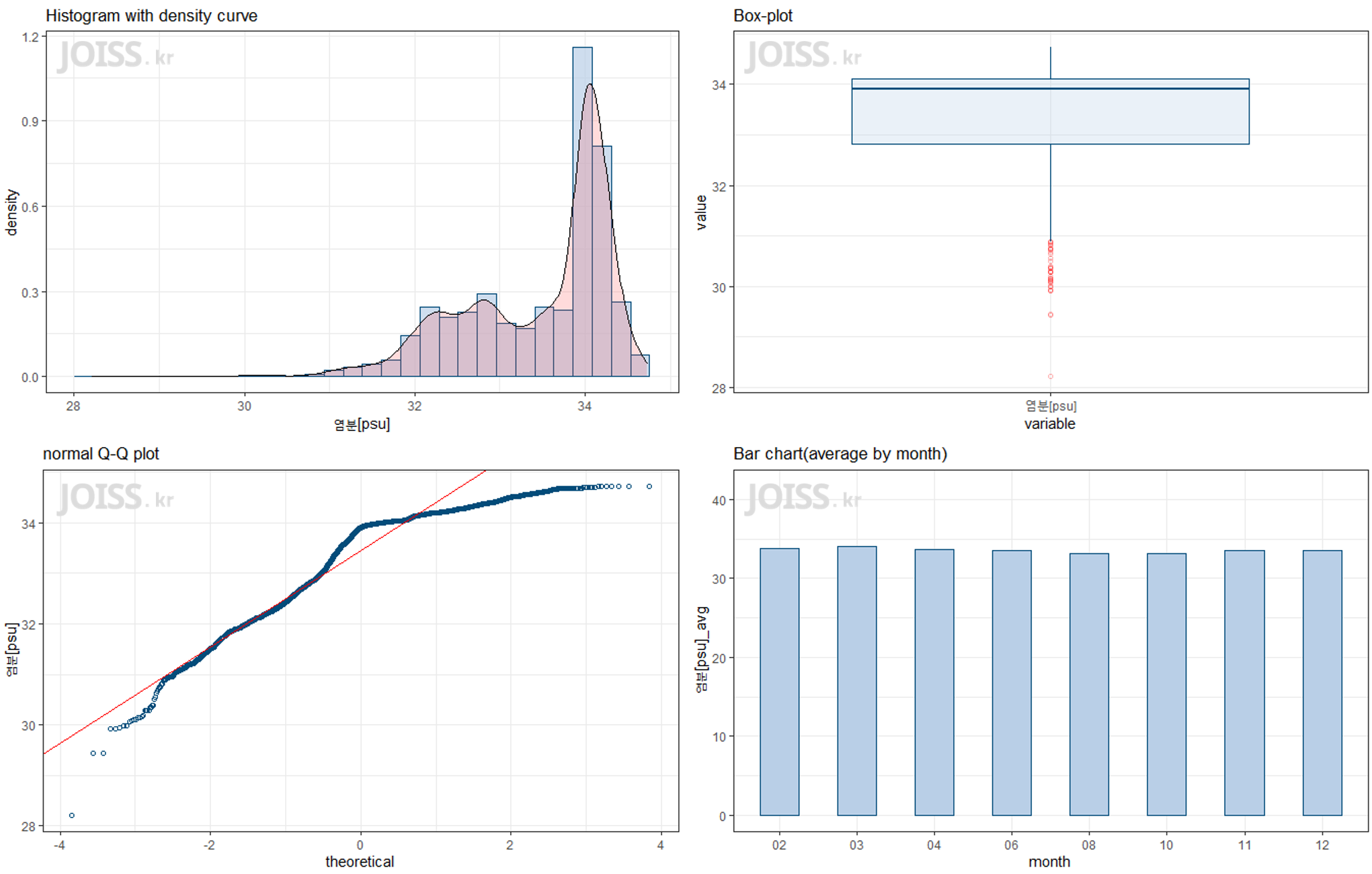
예시의 plot에는 데이터 값의 분포 및 밀도를 확인할 수 있는 histogram, 데이터셋의 outlier를 예상해 볼 수 있는 boxplot, 데이터가 특정분포를 따르는지 확인 가능한 Q-Q plot, 마지막으로 월별데이터의 평균수치를 시각화하여 월별 혹은 계절적 변화를 확인할 수 있는 Bar chart로 구성되어 있습니다.
예시의 이미지 말고도 R에서는 분석가의 재량에 따라 데이터를 다양한 방법으로 시각화 하고 분석할 수 있습니다.
동일한 소스코드를 활용하여 JOISS내 다른 관측자료도 쉽게 시각화 할 수 있습니다.
다음으로는 또다른 JOISS 데이터셋을 활용하여 공간적으로 분석해 보겠습니다.
· 데이터 공간분포 시각화 TOP
R을 활용하여 공간분포 시각화를 구현하기 위해, 이번에는 앞서 사용했던 JOISS데이터셋의 수온자료를 사용해 보겠습니다.
먼저 아래 소스코드를 통해 수온자료만 추출하여 data2변수에 입력합니다.
library(reshape2)library(dplyr)colnames(joiss_data) # JOISS 데이터 컬럼명(항목) 확인## 다운로드 받은 JOISS데이터 수온자료만 추출하여 파라메터에 저장data2 <- melt(data = joiss_data, id = c("Station", "yyyy-mm-dd hh:mm:ss", "Longitude [degrees_east]", "Latitude [degrees_north]", "수심(m)"), measure.vars = c("수온[℃]") # 필요한 항목입력하여 필터 , na.rm = T)data2$`yyyy-mm-dd hh:mm:ss` <- as.POSIXct(data2$`yyyy-mm-dd hh:mm:ss`) |
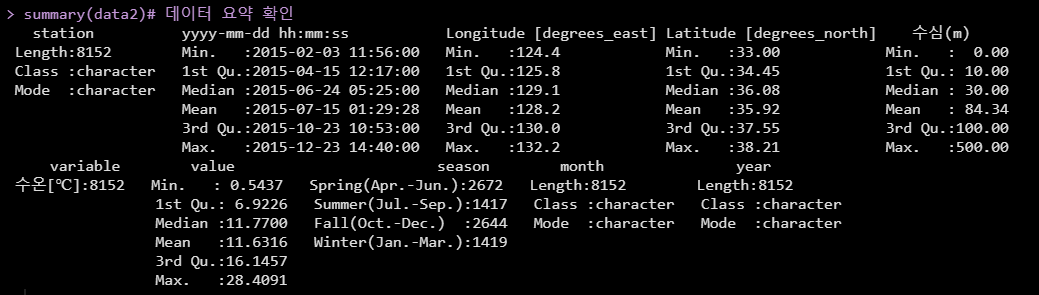
시공간적 분석을 위해 데이터셋에 연도, 월, 계절을 구분할수 있는 컬럼을 추가합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | ## 데이터 핸들링data2 <- data2 %>% mutate(season = format(data2$`yyyy-mm-dd hh:mm:ss`, "%m")) %>% mutate(month = paste(season, "월", sep="")) %>% mutate(year = paste(format(data2$`yyyy-mm-dd hh:mm:ss`, "%Y"),"년",sep="")) data2$season <- gsub("01|02|03", "Winter(Jan.-Mar.)", data2$season) ## => 겨울data2$season <- gsub("04|05|06", "Spring(Apr.-Jun.)", data2$season) ## => 봄data2$season <- gsub("07|08|09", "Summer(Jul.-Sep.)", data2$season) ## => 여름data2$season <- gsub("10|11|12", "Fall(Oct.-Dec.)", data2$season) ## => 가을data2$season <- factor(data2$season, levels=c("Spring(Apr.-Jun.)","Summer(Jul.-Sep.)", "Fall(Oct.-Dec.)","Winter(Jan.-Mar.)")) ## 계절순서# 데이터 확인str(data2) # 데이터 구조 확인summary(data2)# 데이터 요약 확인 |
공간분포 시각화를 구현하기 위해 필요한 지도정보와 통계정보를 변수에 입력합니다.
## 데이터 통계정보 정리set.start.date <- min(data2$`yyyy-mm-dd hh:mm:ss`) set.end.date <- max(data2$`yyyy-mm-dd hh:mm:ss`)data_limit <- data2 %>% summarise(min = min(value),max = max(value),median = median(value),mean = mean(value),sd= sd(value))## 지도정보 불러오기require(ggplot2)require(colorRamps) # 컬러 팔래트 패키지mp <- NULLmapWorld <- borders("world", colour="grey75", fill="grey80") # create a layer of bordersmp <- ggplot() + mapWorld |
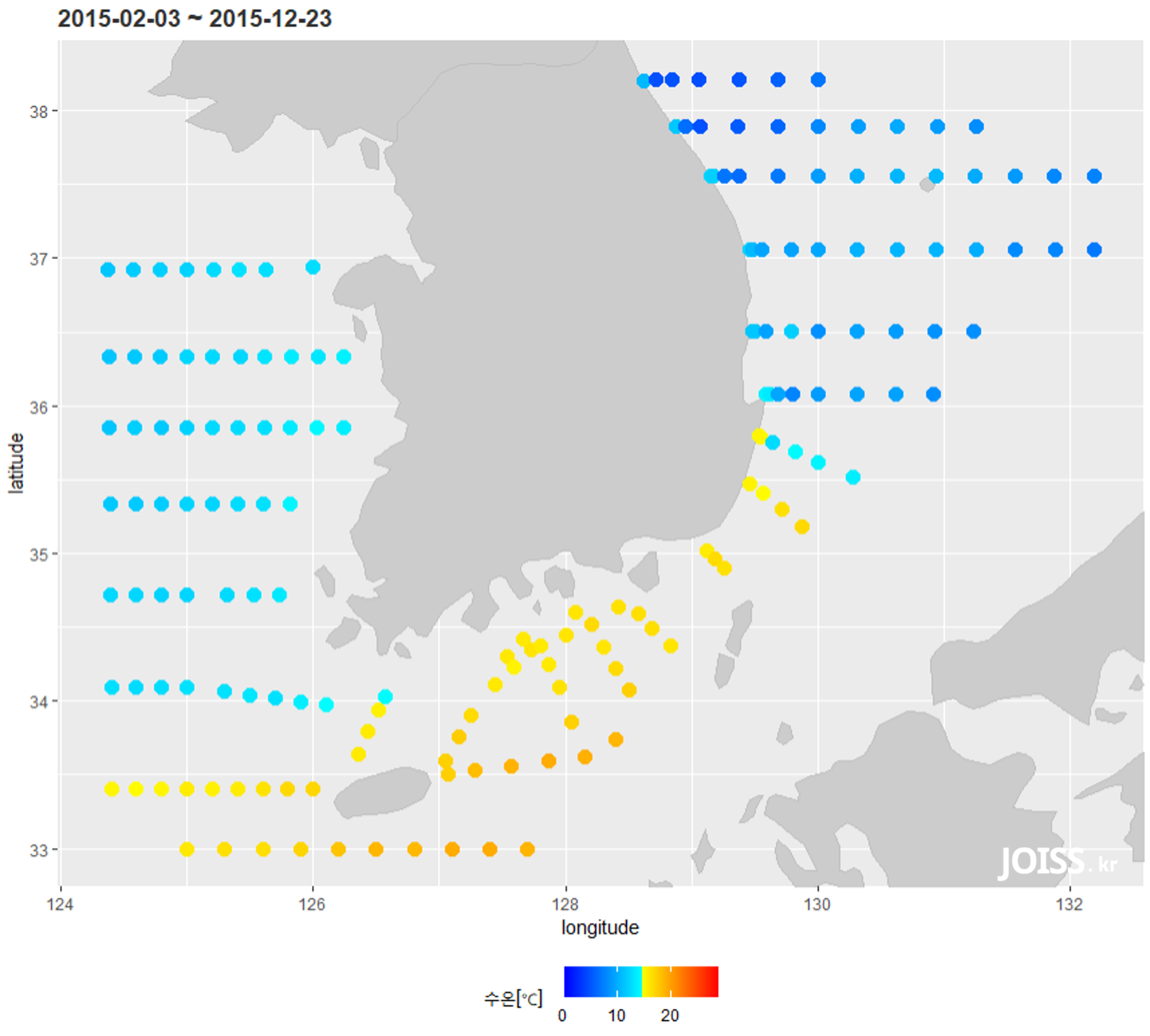
아래의 소스코드를 실행하여 데이터셋의 위치정보와 각 위치별 평균데이터를 색으로 시각화 할 수 있습니다.
############################################################################ spatial plot############################################################################# 공간분포 시각화data.forAnalysis <- data2 %>% group_by(Station) %>% mutate(values.Mean = mean(value)) %>% ungroup()D1 <- unique(data.forAnalysis %>% select(Station,`Latitude [degrees_north]`,`Longitude [degrees_east]`,values.Mean))mp + geom_point(data = D1, aes(x=`Longitude [degrees_east]`, y=`Latitude [degrees_north]`, colour = values.Mean), size = 3.5) + scale_colour_gradientn(colours=blue2red(1000),limits=c(floor(min(data_limit$min)), ceiling(max(data_limit$max)))) + coord_cartesian(ylim = c(min(data2$`Latitude [degrees_north]`), max(data2$`Latitude [degrees_north]`)), xlim = c(min(data2$`Longitude [degrees_east]`), max(data2$`Longitude [degrees_east]`))) + ggtitle(paste(format(min(data.forAnalysis$`yyyy-mm-dd hh:mm:ss`),"%Y-%m-%d") ,"~" ,format(max(data.forAnalysis$`yyyy-mm-dd hh:mm:ss`),"%Y-%m-%d") ,sep=" ")) + theme(plot.title = element_text(face="bold", color="grey20"), strip.background = element_rect(colour="#ffffff", fill="grey60"), strip.text.x = element_text(size=10, color="#ffffff", face="bold")) + labs(color = unique(data2$variable), y = "latitude", x = "longitude") + theme(legend.position = "bottom") |
ggplot2의 facet_wrap() 함수 기능을 사용하여
계절별로 나누어 공간분포를 확인할 수 있습니다.
아래의 소스코드를 실행시켜 계절별 분포를 시각화 합니다.
## 계절별 공간분포 시각화data.forAnalysis <- data2 %>% group_by(Station, season) %>% mutate(values.Mean = mean(value)) %>% ungroup()D1 <- unique(data.forAnalysis %>% select(Station,`Latitude [degrees_north]`,`Longitude [degrees_east]`,values.Mean,season))mp + geom_point(data = D1, aes(x=`Longitude [degrees_east]`, y=`Latitude [degrees_north]`, colour = values.Mean), size = 3) + scale_colour_gradientn(colours=blue2red(1000),limits=c(floor(min(data_limit$min)), ceiling(max(data_limit$max)))) + coord_cartesian(ylim = c(min(data2$`Latitude [degrees_north]`), max(data2$`Latitude [degrees_north]`)), xlim = c(min(data2$`Longitude [degrees_east]`), max(data2$`Longitude [degrees_east]`))) + ggtitle(paste(format(min(data.forAnalysis$`yyyy-mm-dd hh:mm:ss`),"%Y-%m-%d") ,"~" ,format(max(data.forAnalysis$`yyyy-mm-dd hh:mm:ss`),"%Y-%m-%d") ,sep=" ")) + theme(plot.title = element_text(face="bold", color="grey20"), strip.background = element_rect(colour="#ffffff", fill="grey60"), strip.text.x = element_text(size=10, color="#ffffff", face="bold")) + facet_wrap( ~ season, nrow=2)+ labs(color = unique(data2$variable), y = "latitude", x = "longitude") + theme(legend.position = "bottom") |

또한 월별 분포도 아래소스를 실행시켜 시각화 할 수 있습니다.
## 월별 공간분포 시각화data.forAnalysis <- data2 %>% group_by(Station, month) %>% mutate(values.Mean = mean(value)) %>% ungroup()D1 <- unique(data.forAnalysis %>% select(Station,`Latitude [degrees_north]`,`Longitude [degrees_east]`,values.Mean,month))mp + geom_point(data = D1, aes(x=`Longitude [degrees_east]`, y=`Latitude [degrees_north]`, colour = values.Mean), size = 3) + scale_colour_gradientn(colours=blue2red(1000),limits=c(floor(min(data_limit$min)), ceiling(max(data_limit$max)))) + coord_cartesian(ylim = c(min(data2$`Latitude [degrees_north]`), max(data2$`Latitude [degrees_north]`)), xlim = c(min(data2$`Longitude [degrees_east]`), max(data2$`Longitude [degrees_east]`))) + ggtitle(paste(format(min(data.forAnalysis$`yyyy-mm-dd hh:mm:ss`),"%Y-%m-%d") ,"~" ,format(max(data.forAnalysis$`yyyy-mm-dd hh:mm:ss`),"%Y-%m-%d") ,sep=" ")) + theme(plot.title = element_text(face="bold", color="grey20"), strip.background = element_rect(colour="#ffffff", fill="grey60"), strip.text.x = element_text(size=10, color="#ffffff", face="bold")) + facet_wrap( ~ month, nrow=3)+ labs(color = unique(data2$variable), y = "latitude", x = "longitude") + theme(legend.position = "bottom") |
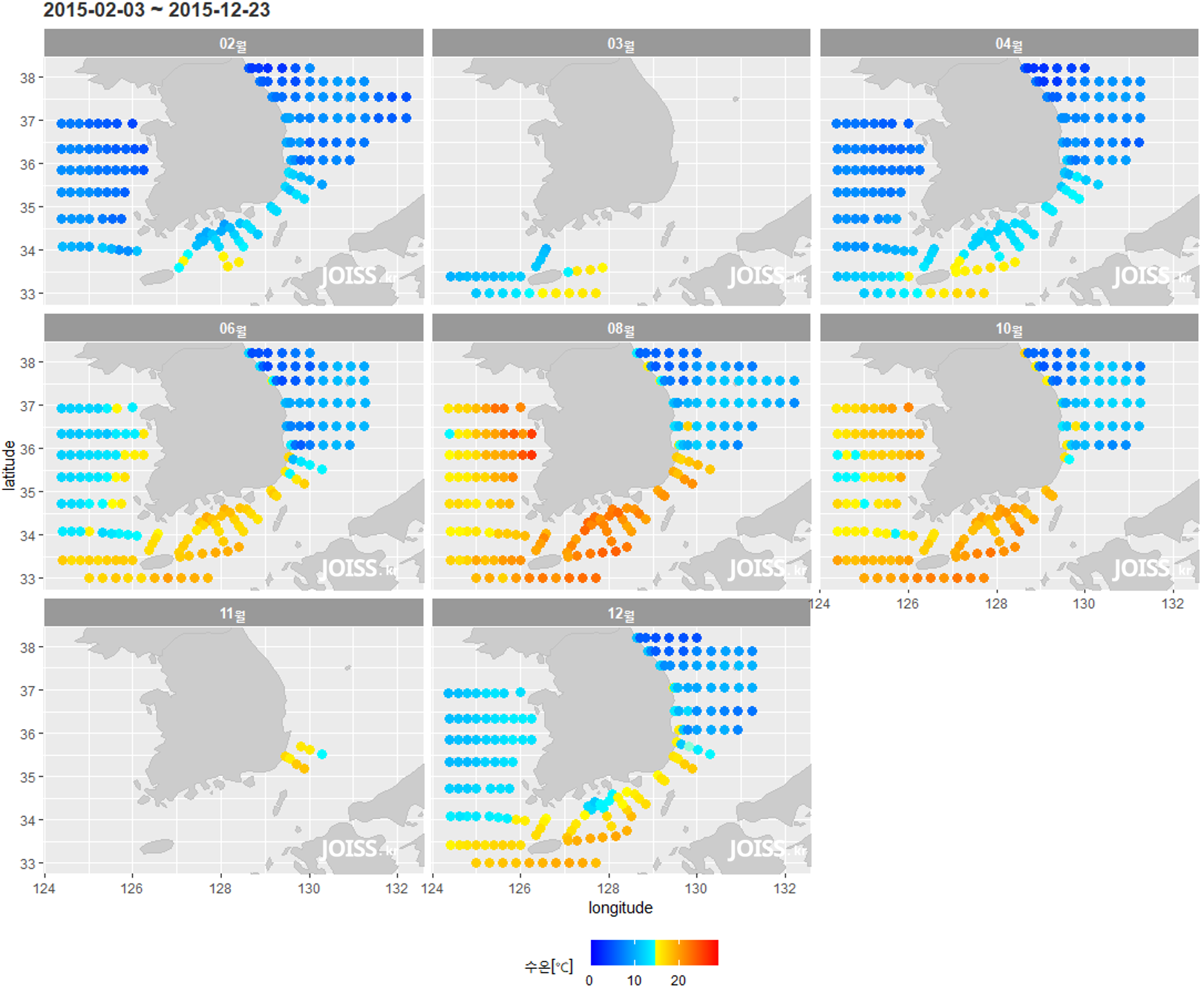
이러한 방법을 통해 데이터의 수치분포를 공간적으로 확인하고 또한 월별, 계절별 특성을 유추해 낼 수 있습니다.
· 데이터 시계열 시각화 TOP
R에서 JOISS 관측자료를 시각화하고 활용하기 위해 샘플 데이터로 다음과 같은 데이터를 준비해 봅시다.
관측자료의 시계열 그래프 시각화를 위해 고정관측소에서 지속적으로 수집되는 샘플데이터를 준비합니다.
본 튜토리얼(데이터 시계열 시각화)에서는 다음과 같은 데이터를 샘플데이터로 사용하였습니다.
검색어 입력 : 해양수질자동측정망_2015
검색 결과 중 ‘해양수질자동측정망_2015_profile_chemical_unknown’ 데이터셋의 체크박스를 클릭 후 ‘ADD TO BASKET’ 버튼을 클릭하면 장바구니 리스트에 추가됩니다. 추가된 데이터는 장바구니 페이지에서 다운로드할 수 있습니다
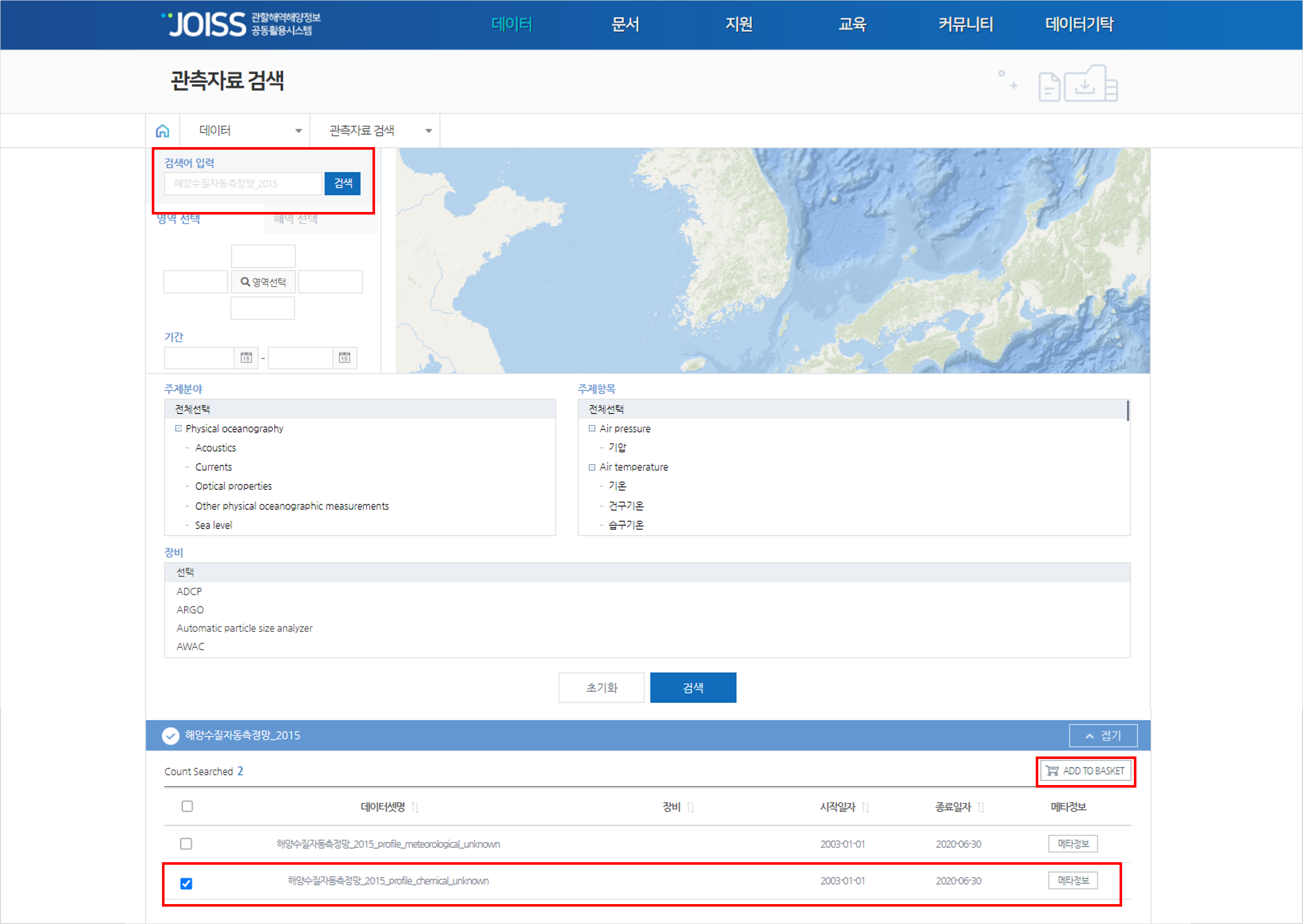
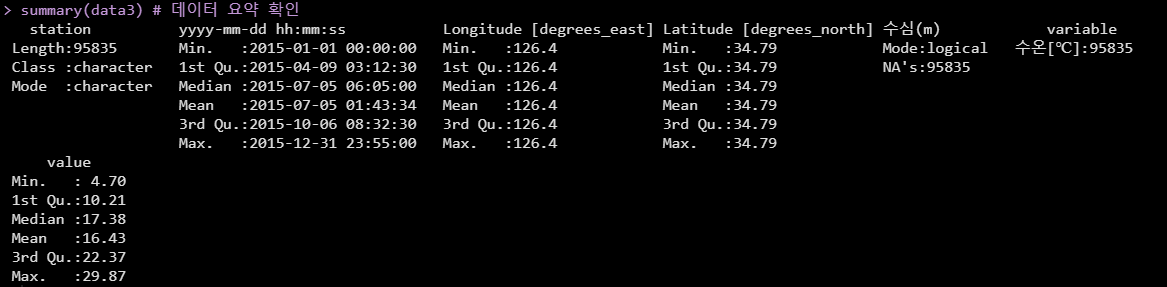
위의 데이터 불러오기 튜토리얼에서 실행하였던 소스코드를 활용하여 확인하고자 하는 정점(영산목포(2측정소))과 항목(수온)을 필터링한 후 data3변수에 입력해보겠습니다.
###########################################################################setwd("C:/Users/myk09/Desktop/R/") # 파일경로 지정 ('\'는 '/'로 변경 필수!)dataset_file_name <- "해양수질자동측정망_2015_profile_chemical_unknown.csv" # 파일명 지정# read csv file with out comment linesremoved_row <- length(grep("/.*", readLines(dataset_file_name)))joiss_data <- read.csv(dataset_file_name, skip = removed_row, header = F, stringsAsFactors=FALSE)joiss_data_colnames <- read.csv(dataset_file_name, skip = (removed_row-1), header = F, nrows = 1, as.is = T)colnames(joiss_data) <- joiss_data_colnames[1, 1:ncol(joiss_data)]joiss_data <- joiss_data[, grepl("_qc", colnames(joiss_data)) == F]rm(removed_row)rm(dataset_file_name)rm(joiss_data_colnames)###########################################################################library(reshape2)colnames(joiss_data) # JOISS 데이터 컬럼명(항목) 확인unique(joiss_data$station) # JOISS 데이터 정점명 확인## 다운로드 받은 JOISS데이터를 확인한 후 필요한 정점 및 데이터만 추출하여 파라메터에 저장(정점 : 영산목포(2측정소), 항목 : 수온)summary(joiss_data) # JOISS 데이터 요약 확인data3 <- melt(data = joiss_data, id = c("Station", "yyyy-mm-dd hh:mm:ss", "Longitude [degrees_east]", "Latitude [degrees_north]", "수심(m)"), measure.vars = c("수온[℃]")# 필요한 항목입력하여 필터 , na.rm = T) %>% filter(station == "영산목포(2측정소)") # 정점 필터data3$`yyyy-mm-dd hh:mm:ss` <- as.POSIXct(data3$`yyyy-mm-dd hh:mm:ss`)str(data3) # 데이터 구조 확인summary(data3) # 데이터 요약 확인 |
정리된 데이터를 R패키지 ggplot2를 이용해 아래 소스코드를 실행하여 시계열 시각화를 그려봅니다.
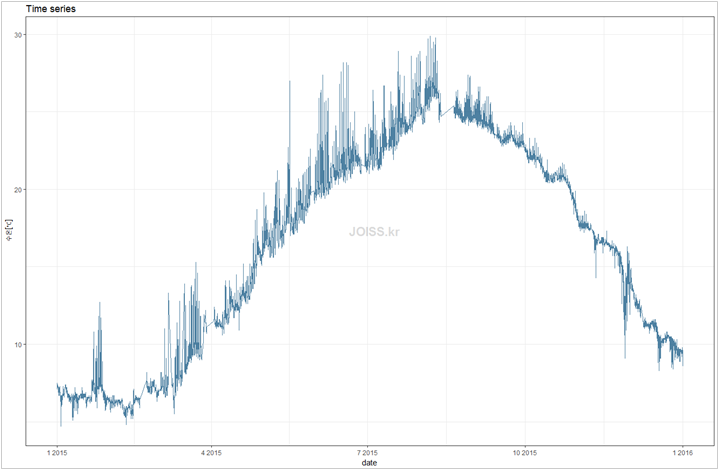
############################################################################# time seriesrequire("ggplot2")# plot #1 time seriesggplot(data3, aes(`yyyy-mm-dd hh:mm:ss`, value)) + theme_bw( ) + geom_line(color = "#034c7a", alpha = 0.7) + xlab("date") + ylab(data3$variable) + ggtitle("Time series") |
이번에는 ggplot2의 다른 기능을 활용하여 데이터의 추세선을 추가해 보겠습니다.
# plot #2 time series point and smooth lineggplot(data3, aes(`yyyy-mm-dd hh:mm:ss`, value)) + theme_bw( ) + geom_point( color = "grey75" ) + geom_smooth() + xlab("date") + ylab(data3$variable) + ggtitle("Time series (with GAM smoother)") |

2015년도 수온자료를 시계열로 표현하고 그위에 Generalized Linear Model 방식의 smoother를 시각화하여 수온이 여름에 높고 겨울에 낮아지는 경향을 파악할 수 있습니다.
이외에도 gplot2 의 geom_smooth() 구문에 method = “lm”, method = “loess”등 옵션을 추가하여 다양한 회귀분석을 적용할 수 있습니다.(옵션의 종류는 geom_smooth()을 입력하여 확인 가능합니다.)
이처럼 2015년도 1년치 데이터를 간단하게 시각화 하는 것만으로도 수온데이터가 계절적 특성을 가진다는 점을 파악할 수 있습니다.
다음으로는 facet_wrap기능을 활용하여 월별로 그래프를 나누어 표현해 보겠습니다.
# time series per monthggplot(data3, aes(`yyyy-mm-dd hh:mm:ss`, value)) + theme_bw( ) + geom_line(color = "#034c7a", alpha = 0.7) + xlab("date") + ylab(data3$variable) + ggtitle("Time series") + facet_wrap( ~ format(data3$`yyyy-mm-dd hh:mm`, "%m"), ncol=3, scales = "free_x") |
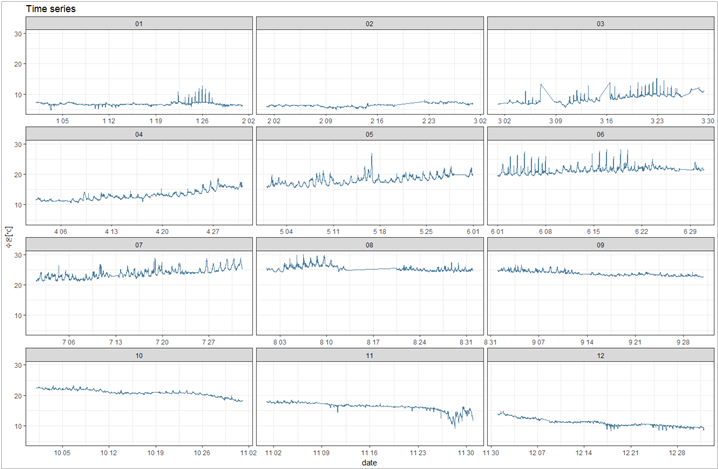
이밖에도 R의 수많은 패키지의 기능을 활용해 분석자가 원하는 시각화를 구현할 수 있습니다.
· 데이터 공간분포 시각화 TOP
이번시간에는 해양학적 전문지식이 없는 상태로 JOISS 데이터를 분석하는 상황을 가정하여, 상향식 접근방식, 데이터기반 객관적 분석, 상관관계 분석, 다변량 분석 및 시각화 등 데이터 분석 절차에 대해 간략하게 소개해 보겠습니다.
튜토리얼에 사용된 JOISS샘플데이터는 ‘JOISS 관측자료 다운로드 및 준비’ 파트에서 사용한 ‘정선해양관측_2015_profile_chemical_unknown’ 데이터 셋을 이용해보겠습니다.
R studio에서 불러올 JOISS데이터가 저장된 폴더의 경로설정 및 파일명 지정 후 데이터를 불러옵니다.
setwd("C:/Users/myk09/Desktop/R/") # 파일경로 지정 ('\'는 '/'로 변경 필수!)dataset_file_name <- "정선해양관측_2015_profile_chemical_unknown.csv" # 파일명 지정# read csv file with out comment linesremoved_row <- length(grep("/.*", readLines(dataset_file_name)))joiss_data <- read.csv(dataset_file_name, skip = removed_row, header = F, stringsAsFactors=FALSE)joiss_data_colnames <- read.csv(dataset_file_name, skip = (removed_row-1), header = F, nrows = 1, as.is = T)colnames(joiss_data) <- joiss_data_colnames[1, 1:ncol(joiss_data)]joiss_data <- joiss_data[, grepl("_qc", colnames(joiss_data)) == F]rm(removed_row)rm(dataset_file_name)rm(joiss_data_colnames)joiss_data <- joiss_data[rowSums(is.na(joiss_data)) != ncol(joiss_data), ] # remove NA rowjoiss_data <- joiss_data[, colSums(is.na(joiss_data)) != nrow(joiss_data)] # remove NA columnsummary(joiss_data) |
앞서 진행하였던 튜토리얼의 소스코드를 활용하여 다운받은 JOISS 데이터를 R에서 불러옵니다.joiss_data라는 변수에 저장한후 데이터에대한 summary를 진행합니다.
summary(joiss_data) |
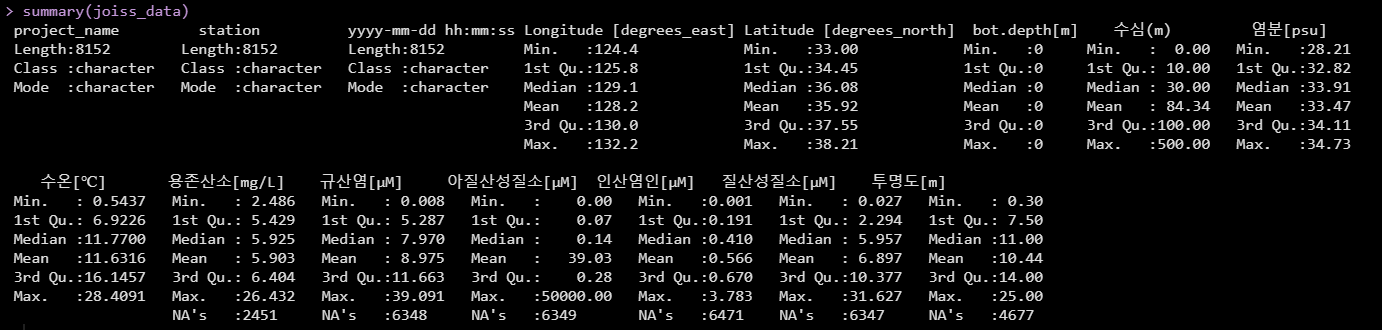
데이터는 기본적으로 character 타입의 메타정보와, 위도 및 경도 그리고 수많은 관측항목데이터로 이루어져 있습니다.
본 튜토리얼에서는 항목별 관계에 대한 지식이 없다는 가정하에 먼저 R Correlation Matrix을 통한 상관관계분석을 진행해 보겠습니다.
먼저 데이터셋에 포함된 항목들의 상관관계 시각화를 위한 데이터 전처리를 진행합니다.
전처리 진행시 불필요한 문자형 데이터컬럼은 제외하고 수치형 컬럼으로만 데이터셋을 준비합니다.
사용하고 있는 샘플데이터에는 문자형 데이터 컬럼이 없지만 JOISS 제공되고 있는 데이터셋 중 문자형 데이터 컬럼이 있을 수 있기에 해당 컬럼을 제외하는 코드를 실행시킨 후 진행하도록 하겠습니다.
## 상관관계 분석을 위한 데이터 전처리data_tmp <- joiss_data %>% select(-contains("_code"))data_tmp <- data_tmp[, c(7:ncol(data_tmp))] # project name부터 수심을 뺀 데이터 저장data_cormat <- round(cor(data_tmp, use = "complete.obs", method = c("pearson")),2)library(reshape2)data_4_cor_mtrx <- melt(data_cormat, factorsAsStrings = F) |
data_4_cor_mtrx변수에 저장된 정보를 가지로 ggplot2패키지를 이용해 상관관계를 시각화하여 보겠습니다.
아래의 소스코드를 실행합니다.
## Correlationrequire(ggplot2)ggplot(data = data_4_cor_mtrx, aes(Var2, Var1, fill=value)) + geom_tile() + ggtitle("Correlation Analyses") |

보다 쉬운 데이터 파악을 위해 ggplot2의 옵션을 추가하여 보겠습니다.
아래의 소스코드를 실행하여 색상, 상관지수 등 옵션을 추가 합니다.
## 항목별 상관관계 시각화(옵션추가)# Get upper triangleget_upper_tri <- function(cormat){ cormat[lower.tri(cormat)]<- NA return(cormat)}upper_tri <- get_upper_tri(data_cormat)data_4_cor_mtrx2 <- melt(upper_tri, na.rm = TRUE)############ggplot(data = data_4_cor_mtrx2, aes(Var2, Var1, fill=value)) + theme_bw( ) + geom_tile(color = "white")+ scale_fill_gradient2(low = 'blue', mid = 'white', high = 'red', midpoint = 0, na.value = "grey90", limit = c(-1,1), space = "Lab") + geom_text(aes(Var2,Var1,label=value)) + theme(axis.ticks = element_blank(), axis.text.x = element_text(angle = 270, hjust = 0), axis.title = element_blank(), legend.title = element_blank()) + ggtitle("Correlation Analyses") |
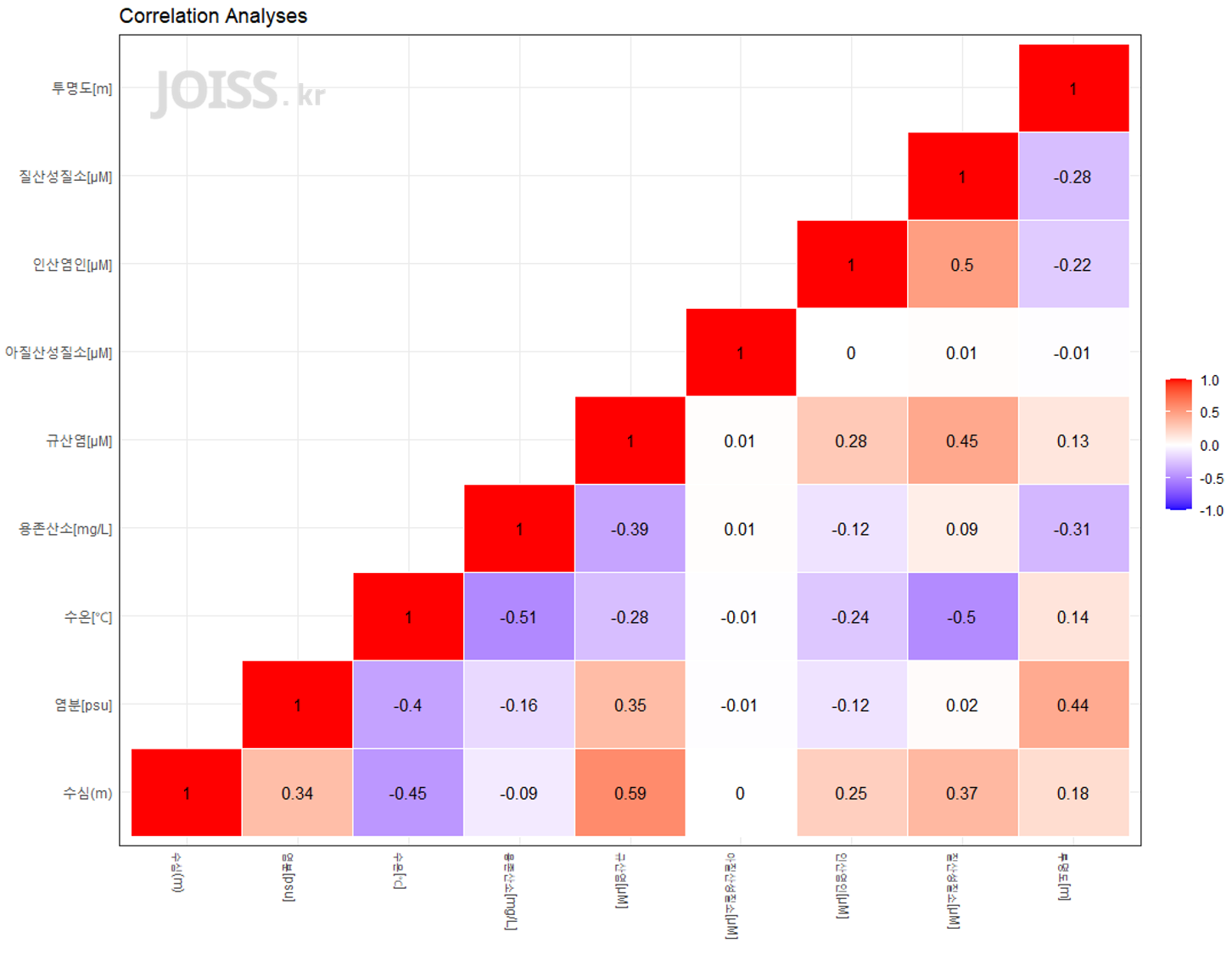
상관계수는 -1 ≤ ρ ≤ 1 의 범위의 값을 가지게 됩니다.
상관계수 ρ가 +1에 가까울수록 강한 양의 상관관계를 가지며, -1에 가까울수록 강한 음의 상관관계를 가진다고 볼 수 있습니다.
상관계수 ρ = 0 이면 두 변수간의 상관관계는 없으나 비상관관계를 가질 가능성도 있습니다.
예를 들면, 수심과 수온의 경우 음의 상관관계를, 수심과 염분의 경우 양의 상관관계를 이루고 있음을 알 수 있습니다.
보다 상세한 분석을 위해 수심, 수온, 염분 자료만 별도의 변수로 저장합니다.
## data handlinglibrary(reshape2)colnames(joiss_data) # JOISS 데이터 컬럼명(전체항목) 확인data4 <- melt(data = joiss_data, id = c("Station", "yyyy-mm-dd hh:mm:ss", "Longitude [degrees_east]", "Latitude [degrees_north]", "수심(m)"), measure.vars = c("수온[℃]", "염분[psu]") # 필요한 항목입력하여 필터 ,na.rm = T)data4$`yyyy-mm-dd hh:mm:ss` <- as.POSIXct(data4$`yyyy-mm-dd hh:mm:ss`)data4$variable <- as.character(data4$variable)unique(data4$variable) # 항목 확인 |
준비된 데이터 셋을 가지고 수심과 수온의 관계, 수심과 염분의 관계를 시각화 해보겠습니다.
아래의 소스코드를 실행하여 시각화 결과를 확인할 수 있습니다.
## plotrequire(dplyr)data4_tmp <- data4 %>% filter(variable == "수온[℃]")data4_sal <- data4 %>% filter(variable == "염분[psu]")############################################################################# create multiplot functionmultiplot <- function(..., plotlist=NULL, file, cols=1, layout=NULL) { require(grid) # Make a list from the ... arguments and plotlist plots <- c(list(...), plotlist) numPlots = length(plots) # If layout is NULL, then use 'cols' to determine layout if (is.null(layout)) { # Make the panel # ncol: Number of columns of plots # nrow: Number of rows needed, calculated from # of cols layout <- matrix(seq(1, cols * ceiling(numPlots/cols)), ncol = cols, nrow = ceiling(numPlots/cols)) } if (numPlots==1) { print(plots[[1]]) } else { # Set up the page grid.newpage() pushViewport(viewport(layout = grid.layout(nrow(layout), ncol(layout)))) # Make each plot, in the correct location for (i in 1:numPlots) { # Get the i,j matrix positions of the regions that contain this subplot matchidx <- as.data.frame(which(layout == i, arr.ind = TRUE)) print(plots[[i]], vp = viewport(layout.pos.row = matchidx$row, layout.pos.col = matchidx$col)) } }}######################################################################################################################################################p1 <- ggplot(data4_tmp, aes(`수심(m)`,value)) + theme_bw( ) + geom_point(position = "jitter", color = "grey85", alpha = 0.3) + geom_smooth(method = "loess", color = "#0783c9", size = 1.2 ) + ylab(unique(data4_tmp$variable)) + coord_flip() + scale_x_reverse() + ggtitle("Temperature vs Depth (with loess smoother)")p2 <- ggplot(data4_sal, aes(`수심(m)`,value)) + theme_bw( ) + geom_point(position = "jitter", color = "grey85", alpha = 0.3) + geom_smooth(method = "loess", color = "#14a085", size = 1.2 ) + ylab(unique(data4_sal$variable)) + coord_flip() + scale_x_reverse() + ggtitle("Salinity vs Depth (with loess smoother)")# muliple plot multiplot(p1, p2, cols=2) |
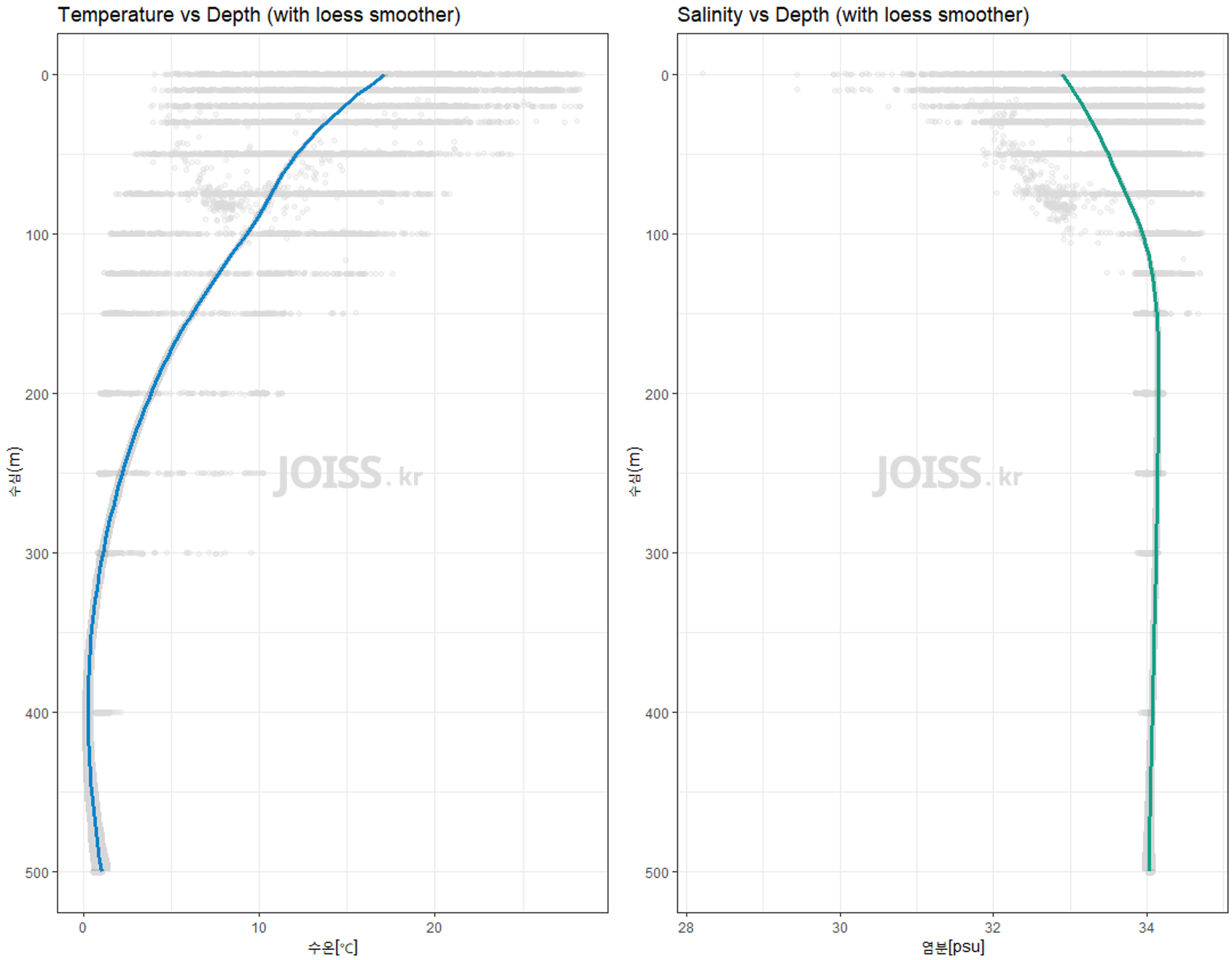
위 결과를 통해 수심이 증가할수록 수온이 낮아지는 경향을 보이며, 반대로 수심이 증가할수록 염분이 증가하는 경향을 파악할 수 있습니다.
이와 같이 상관관계 분석을 통해 파라메터간 특성을 파악하고 분석하여 결과를 도출하는 시간을 가져보았습니다.
이상으로 JOISS 데이터의 R 활용 튜토리얼을 마치겠습니다.
감사합니다.
TOP


